
Pulsar的消息保留和过期策略
Pulsar的消息保留和过期策略
)
导读
Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构设计,支持多租户、持久化存储、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高可扩展性等流数据存储特性。
默认情况下,Pulsar Broker 会对消息做如下处理:
- 列表项当消息被 Consumer 确认之后,会立即执行删除操作。
- 对于未被确认的消息会存储到 backlog 中。
但是,很多线上的生产环境下,这种默认行为并不能满足我们的生产需求,所以,Pulsar 提供了如下配置策略来覆盖这些行为:
- Retention 策略:用户可以将 Consumer 已经确认的消息保留下来。
- TTL 策略:对于未确认的消息,用户可以通过设置 TTL 来使未确认的消息到达已经确认的状态。
Retention 策略
Retention 策略的设置提供了两种方式:
- 消息的大小,默认值:defaultRetentionSizeInMB=0
- 消息被保存的时间,默认值:defaultRetentionTimeInMinutes=0
我们可以在 broker.conf 中对这两项内容进行配置也可以通过命令行的形式。上文提到过,这两种策略的设置,都是在 NameSpace 的级别进行设置,所以当我们使用命令行配置时,使用 NameSpaces 来进行配置,具体如下:
1 | bin/pulsar-admin --admin-url http://*.*.*.*:8080 namespaces set-retention b2d/2024-7 --size -1 --time 1h |
如上所示:我们可以通过 -s 或者 -t 来指定我们需要配置的大小或者时间。
当你设置 Retention 策略之后,可以通过如下命令来查看具体的信息:
1 | bin/pulsar-admin --admin-url http://*.*.*.*:8080 namespaces get-retention b2d/2024-7 |
Backlog
backlog 是未被确认消息的集合,它有一个大前提是,这些消息所在的 Topic 是被 Broker 所持久化的,在默认情况下,用户创建的 Topic 都会被持久化。换句话说,Pulsar Broker 会将所有未确认或者未处理的消息都存放到 backlog 中。
同样的,我们可以在 NameSpace 级别对 backlog 的大小进行配置。需要注意的是,对 backlog 进行配置时,我们需要明确以下两点:
- 在当前的 NameSpace 下,每一个 Topic 允许的大小是多少
- 如果超过设定的 backlog 的阈值,将会执行哪些操作
当超过设定的 backlog 的阈值,Pulsar 提供了以下三种策略供用户选择: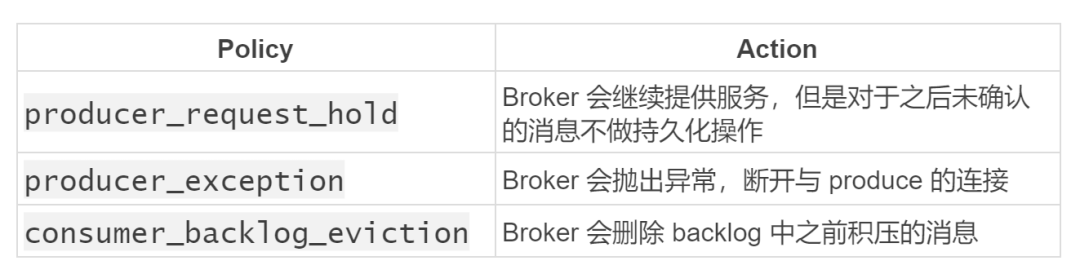
你可以通过 set-backlog-quota 在 NameSpace 级别对 backlog 进行配置,具体如下:
1 | # ./bin/pulsar-admin namespaces set-backlog-quota |
如上所示,set-backlog-quota 提供了两个参数,-l 用来指定你设置 backlog 的大小,-p 用来指定,当超过你设置的 backlog 的阈值之后,Broker 将会执行的策略。
当你设置 backlog 之后,可以通过如下命令,查看相应的信息:
1 | bin/pulsar-admin --admin-url http://*:8080 namespaces get-backlog-quotas b2d/2024-7 |
如果你期望取消 backlog 的配置,可以使用如下命令:
1 | $ pulsar-admin namespaces remove-backlog-quota [your tenant]/[your namespace] |
当有消息积压时,你可以通过 clear-backlog 来清除积压的消息。清除 backlog 中积压的消息是相对危险的操作,所以系统会提示你,是否确认要删除 backlog 中的消息, clear-backlog 提供了 -f(–force) 的参数来屏蔽该提示。
1 | $ pulsar-admin namespaces clear-backlog [your tenant]/[your namespace] |
Time To Live (TTL)
默认情况下,Pulsar 会持久化所有未被确认的消息。如果未被确认的消息有很多,这种策略会造成大量的消息被积压,导致磁盘空间增大。有些场景下,消息并不需要被持久化,用户更期望的行为是,将这些未被确认的消息直接丢弃。这种情况下,你可以通过设置 TTL 使得未被确认的消息进入到被确认的状态,当超过设定的 TTL 时间之后,配合相应的 Retention 策略将消息丢弃。
TTL 的一个典型使用场景是,当 Consumer 由于某些原因出现故障,不能正常消费消息,这时 Producer 还在不断的往 Topic 中生产消息,会造成 Topic 中有大量的未确认的消息出现,这时你可以通过设置 TTL 将这些未确认的消息变为已确认的状态。
同样的,你可以在 Namesapce 级别下,通过指定 set-message-ttl 对 TTL 进行设置,具体命令如下:
1 | root@/pulsar# ./bin/pulsar-admin namespaces set-message-ttl |
如上所示,set-message-ttl 只有一个参数 -ttl,单位为秒,默认值为 0。
当你设置 TTL 策略之后,可以通过 get-message-ttl 查看相应的配置信息,具体如下:
1 | bin/pulsar-admin --admin-url http://*.*.*.*:8080 namespaces get-message-ttl b2d/2024-7 |
TTL、Backlog 与 Retention 的区别和联系
在上述的描述过程中,可以发现,TTL 只去处理一件事情,将未被确认的消息变为被确认的状态 ,TTL 本身不会去涉及相应的删除操作,具体如下图所示: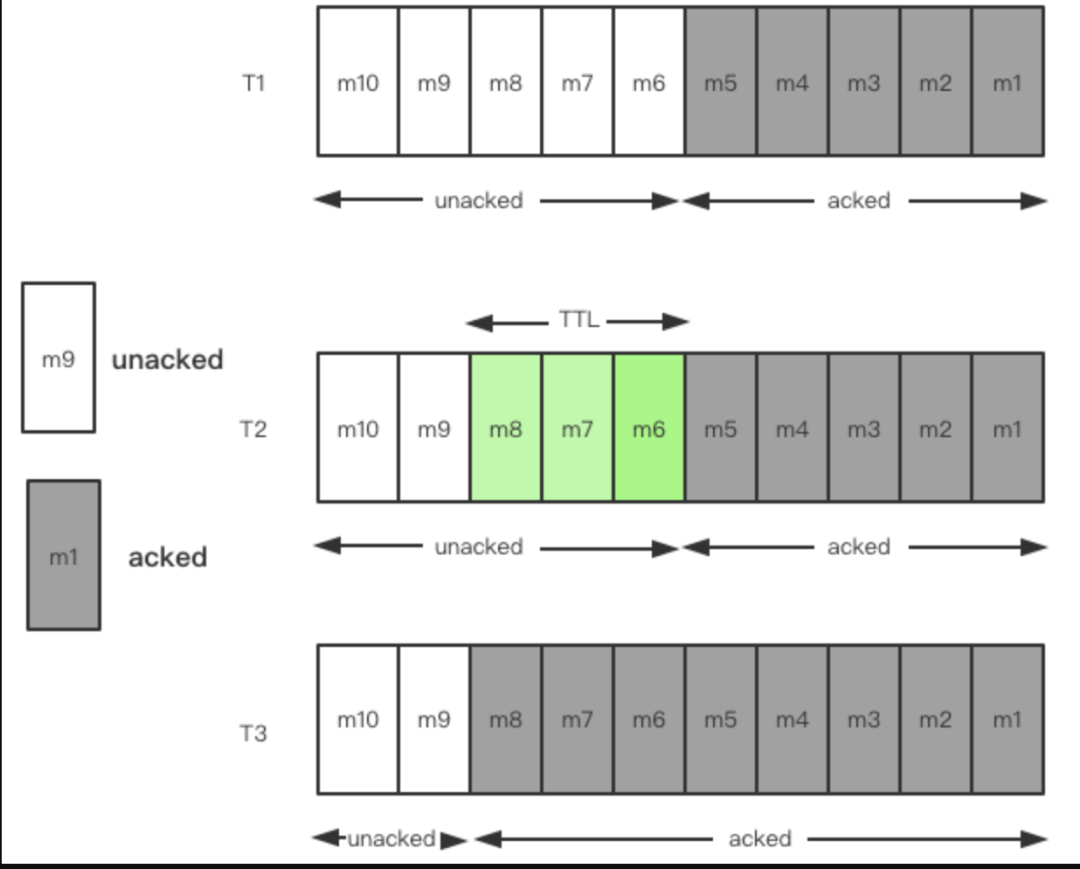
- 列表项在 T1 阶段,m1-m5 这 5 条消息被确认,m6-m10 这 5 条消息未被确认
- 列表项在 T2 阶段,对 m6、m7、m8 这三条消息设置 TTL 策略
- 列表项在 T3 阶段,到达 TTL 设定的阈值,m6、m7、m8 这三条消息被确认
通过上图可以看到,对于 backlog 中未被确认的消息,当你设置 TTL 之后,会将未确认消息的状态变为确认的状态。TTL 在这里所起到的作用就是将消息的 Cursor 从 m5 移动到 m8,m6、m7、m8 这三条消息变为已确认状态。
默认情况下,Pulsar Broker 会将所有未确认的消息持久化到 backlog 中。TTL 的功能是,你可以将这些未被确认的消息变为被确认的状态,而 Retention 所关注的点是,当消息处于被确认的状态时,你可以对已确认的消息进行的保留策略是什么。换句话说,backlog 是针对未确认的消息,Broker 所做的处理是什么。Retention 是针对已确认的消息,Broker 所做的保留策略是什么。
TTL 与死信队列
死信队列的相关介绍在此不做赘述。
在生产环境中,有时可能遇到质量差的数据是由于上游的原因导致的,必须由上游来解决,继续尝试处理其它的消息已经没有意义,这时候用户希望在发生错误时立即停止处理。Pulsar 中提供了一种特殊的 Topic——死信队列。
死信队列与 TTL 都可以将未确认的消息变为已确认的状态。他们之间主要的不同在于,在上图中的 T2 阶段,TTL 只是将未确认的消息变为已确认的状态,死信队列的做法是将消息丢弃到死信队列中,m6、m7、m8 这三条消息变为被确认的状态。m9、m10 这两条有效消息会正常处理,Broker 也会继续运行。之后,你可以从死信队列中检查无效消息,并根据需要忽略或修复并重新处理。用户可以根据自己的需求来确定未确认的消息是通过 TTL 的形式将其变为确认状态还是通过死信队列的方式来实现,依据的主要标准就是看你需不要处理消费不了的消息。
使用问题
- 场景一:
启动 Producer 往 Broker 发送消息,设置了 TTL ,没有启动 Consumer,同时设置了 Retention 策略为半小时,到达 Retention 的阈值之后,发现设置 TTL 的消息并没有被移除,这是为什么呢?
在上述场景中,有一个问题需要注意,没有启动 Consumer,在上面我们说到,TTL 是将消息设置的 Cousor 向前移动,如果没有启动 Consumer,相当于 Cousor 没有被初始化,也就是如果没有 Consumer,你就没有必要去设置 TTL。
- 场景二:
我设置了Retention 策略,但是到达了 Retention 的阈值,Topic 中的数据并没有被删除掉,这是为什么呢?
这个是 Pulsar 内部的一个实现机制,在 Pulsar 中 Topic 是一个逻辑的概念,一个 Topic 对应一个 manage ledger,当你写数据的时候,实际上是将数据写到了 ledger 中,还记得在之前很多文章中提到的有关 Pulsar 设计的一个核心所在:在Pulsar中,所有的操作都是异步的 ,所以当 Retention 到达指定阈值之后,是否删除对应 ledger 中的数据,这个操作也是异步的。delete 的操作是不会对当前 active 的 ledger 执行的。只有当数据写满了当前的 ledger ,ledger 发生切换时,才会去真正的执行 retention 策略。
如果想要强制执行,可以使用 pulsar-admin 将当前的 ledger 强制卸载,迫使其发生 ledger 的切换。
- 场景三:
集群磁盘爆炸原因与解决
当bookies的硬盘被打到95%以上,会自动把bookies给设置为readonly的。
1.设置pulsar服务器,磁盘占用90%P0告警
2.当bookie进入只读模式,处理方式
(1)查看磁盘占用趋势以及消费堆积,对比大致可以得出堆积的topic
(2)手动修改(减小)过期策略,战略性放弃堆积消息 bin/pulsar-admin namespaces set-message-ttl b2d/2024 –messageTTL 1(此处设置的1秒,具体看情况 )
(3)手动重启bookie,观察磁盘占用情况,bin/pulsar-daemon stop/start bookie
(4)若以上生效,则手动修改过期策略,再次重启bookie
或者
(1)conf/bookkeeper.conf:httpServerEnabled=false改为true,启用api调用触发gc
(2)触发命令:curl -X PUT -d ‘http://localhost:8080/api/v1/bookie/gc‘
通过 BookKeeper 暴露的 Http 调用 Admin Rest API 接口来触发 GC 请求。这个操作在日常急救运维中很常见,比如 Bookie 磁盘内存突然大幅度上涨,用户想要紧急回收数据,那么就可以跳过 Minor GC 和 Major GC 检查周期,手动触发 GC 来释放磁盘空间。
或者
(1)readOnlyModeEnabled=true diskUsageThreshold=0.95,将readOnlyModeEnabled改为false,这样当磁盘达到阈值不会进入只读模式,但要尽快处理磁盘占用 ,否则pulsar将会不可用;此步骤可以配合以上步骤使用
参考文献:
https://cloud.tencent.com.cn/developer/article/2245703
https://cloud.tencent.com/developer/article/1899216
 wechat
wechat alipay
alipay


